Vibe Coding의 실체: 설계 30분, 디버깅 5시간
목차
“알아서 해줘”로는 안 됐다. 사람이 설계하고 AI가 구현하고, 결과를 눈으로 확인하며 하나하나 고치는 반복, 그게 vibe coding의 실체였다. 3개 분석 도구, 6시간, 커밋 35회.
블로그 트래픽을 분석하려면 Cloudflare 대시보드를 열고, GoatCounter를 열고, Workers KV 데이터를 따로 확인해야 했다. 세 군데를 번갈아 보는 건 귀찮을 뿐 아니라, 전체 그림을 파악하기도 어렵다. 이 세 데이터소스를 하나의 대시보드로 통합하는 작업을 Claude Code와 함께 vibe coding으로 진행했다.
“알아서 해줘”로 시작했다가 실패하고, 직접 청사진을 그린 뒤 35커밋에 걸쳐 하나씩 고쳐간 과정이다. 디버깅의 70%는 AI의 한계가 아니라 사람의 사전 설계 부재에서 왔다.
배경
블로그(blog.neocode24.com)의 트래픽 분석을 3개 도구로 나눠서 구성하고 있었다.
- Cloudflare Web Analytics: Core Web Vitals(LCP, INP, CLS), 방문, 페이지 뷰를 Real User Monitoring(RUM) 방식으로 수집한다.
- GoatCounter: 브라우저, OS, 위치, 언어 등 사용자 환경 통계를 수집한다.
- Analytics Engine: Cloudflare Workers에서 자체 pageview/like 이벤트를 기록한다. 누적 조회수와 좋아요는 Workers KV에 영구 저장된다.
Core Web Vitals(CWV): Google이 정의한 사용자 경험 핵심 지표 3종으로, 검색 순위에도 반영된다.
- LCP(Largest Contentful Paint): 가장 큰 콘텐츠가 화면에 그려지는 시간. 좋음 ≤ 2.5s
- INP(Interaction to Next Paint): 사용자 입력 후 다음 프레임까지 지연. 좋음 ≤ 200ms
- CLS(Cumulative Layout Shift): 레이아웃이 밀리는 정도. 좋음 ≤ 0.1
Telegram AI 어시스턴트에게 “블로그 트래픽 분석을 쉽게 볼 수 있는 방법”을 물었더니 세 가지를 제안했다. Cloudflare + GoatCounter 데이터를 통합 대시보드로 만들기, Workers API로 데이터 집계하기, Telegram으로 주간 종합 리포트 자동 발송하기. 이 중 앞의 두 가지를 먼저 구현하기로 했다.
데이터 수집 구조
사용자가 블로그에 접속하면 4개 시스템이 각각 독립적으로 데이터를 수집한다. 대시보드는 Workers API가 이 4개 소스를 한 번에 조회하여 통합 표시하는 구조다.
flowchart TB
subgraph 사용자["사용자 브라우저"]
visit["블로그 접속"]
end
subgraph cf["Cloudflare Edge"]
zone["Zone Analytics<br/><small>HTTP 요청, 4xx/5xx</small>"]
rum["Web Analytics RUM JS<br/><small>CWV, 방문, PV, 로드</small>"]
end
subgraph external["외부 수집"]
gc["GoatCounter gc.js<br/><small>브라우저, OS, 화면, 위치, 언어</small>"]
end
subgraph workers["Cloudflare Workers"]
api["Workers API<br/>/api/views · /api/likes"]
ae["Analytics Engine<br/><small>pageview/like 시계열</small>"]
kv["Workers KV<br/><small>누적 조회수/좋아요</small>"]
end
subgraph dashboard["대시보드 조회"]
dash["dashboard.astro<br/>/api/views/dashboard"]
end
visit -->|"Proxied 요청"| zone
visit -->|"RUM JS 자동 로드"| rum
visit -->|"gc.js 호출"| gc
visit -->|"pageview/like 이벤트"| api
api --> ae
api --> kv
dash -->|"Analytics Engine SQL"| ae
dash -->|"GraphQL"| rum
dash -->|"GraphQL"| zone
dash -->|"REST API"| gc
dash -->|"KV get"| kv
대시보드는 이 모든 소스를 Workers API 하나의 엔드포인트(/api/views/dashboard?period=1d|7d|30d)로 집계하여 프론트엔드에 전달한다.
| 수집 항목 | 데이터소스 | 수집 방식 | 대시보드 위치 |
|---|---|---|---|
| HTTP 요청수, 4xx, 5xx | Zone Analytics | Edge 자동 | CWV 그리드 2행 |
| CWV (LCP/INP/CLS) | CF Web Analytics | RUM JS | CWV 게이지바 + 상세 카드 |
| 방문, 페이지 뷰, 로드 시간 | CF Web Analytics | RUM JS | 요약 카드 + 스파크라인 |
| 페이지별 조회 추이 | Analytics Engine | Workers API 호출 | 추이 차트, 인기 페이지 시계열 |
| 좋아요 이벤트 | Analytics Engine | Workers API 호출 | 추이 차트 |
| 누적 조회수/좋아요 | Workers KV | Workers API 호출 | 요약 카드, 인기 페이지 누적 |
| 브라우저, OS, 화면크기 | GoatCounter | gc.js | 하단 5열 |
| 위치, 언어 | GoatCounter | gc.js | 하단 5열 |
초도본: AI에게 “알아서 해줘”의 결과
처음에는 “심플하게 Cloudflare + GoatCounter 데이터를 합쳐서 보여줘” 수준으로 시작했다. 점진적으로 개선하면 될 거라 생각했다.
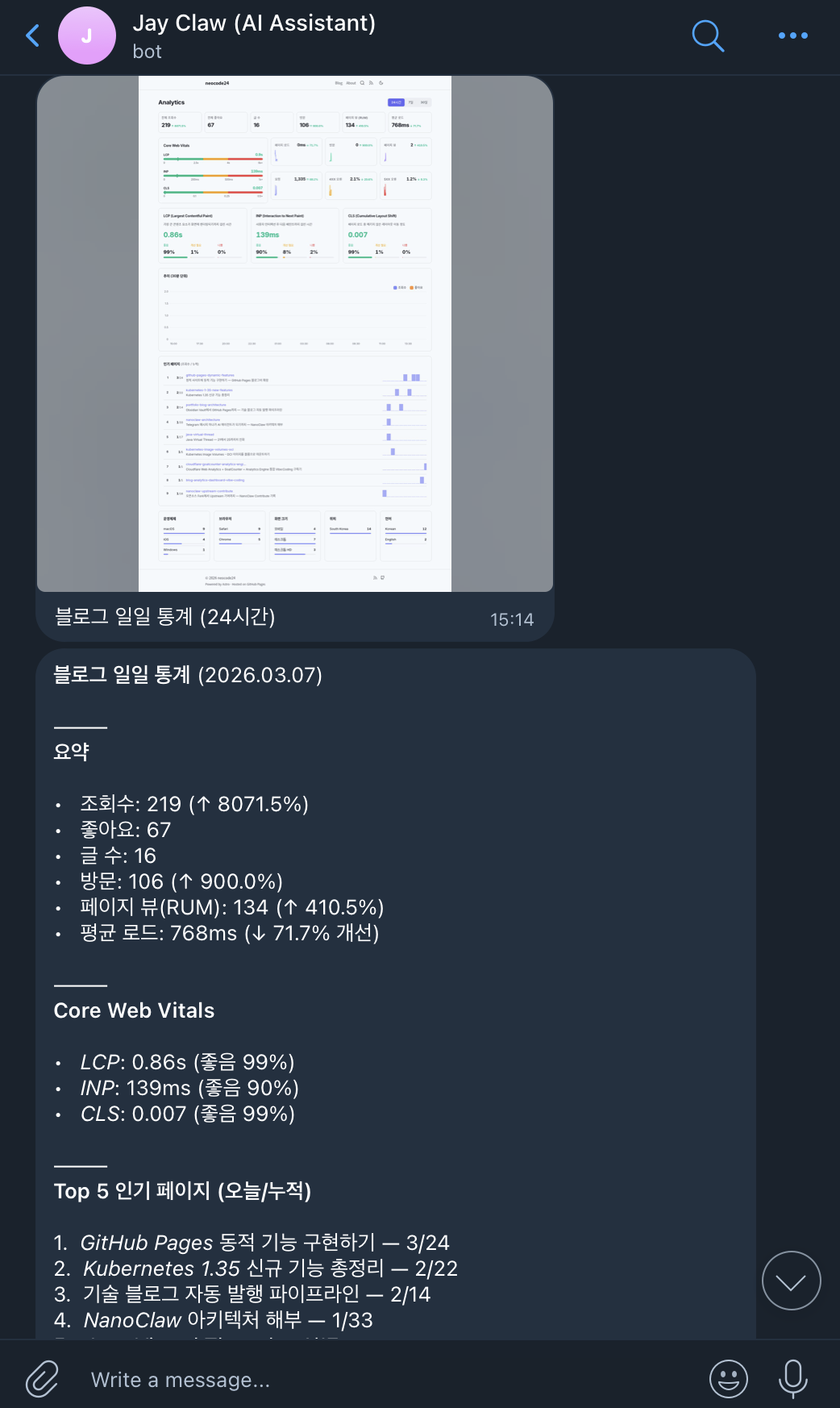
AI가 만든 첫 버전은 CWV를 링 게이지(원형 도넛) 3개로 표시하고, 추이는 일별 막대 차트, 인기 페이지는 slug과 숫자를 단순 나열하는 구성이었다. GoatCounter 데이터도 브라우저, OS, 화면크기 3종만 연동되었다.
기능적으로 동작했지만, Cloudflare Web Analytics 대시보드와 비교하면 정보 밀도가 낮고 디자인이 투박했다. 프롬프트의 시작(의도)은 좋았지만, AI가 자체 판단으로 만든 결과물의 품질이 원하는 수준에 미달했다.
상세 프롬프트: 사람이 설계하고, AI가 구현한다
초도본을 보고 “그냥 해줘” 수준으로는 안 된다고 판단했다. 어떤 정보를 어떤 배치로 보고 싶은지 직접 구상하기로 했다. Cloudflare Web Analytics 대시보드를 레퍼런스 삼아 페이지 레이아웃 초안을 PPT와 이미지로 작성하고, 각 영역의 데이터소스와 표현 방식을 일일이 지정한 프롬프트를 전달했다.
- 요약 카드 6열: 전체 조회수, 좋아요, 글 수, 방문, PV, 평균 로드
- CWV 2행 구조: 1행은 스펙트럼 게이지바 + 스파크라인 3개(페이지 로드, 방문, 페이지 뷰), 2행은 LCP/INP/CLS 상세 카드(좋음/개선필요/나쁨 비율)
- 추이 차트: 기간별 동적 X축(5분/시간/일)
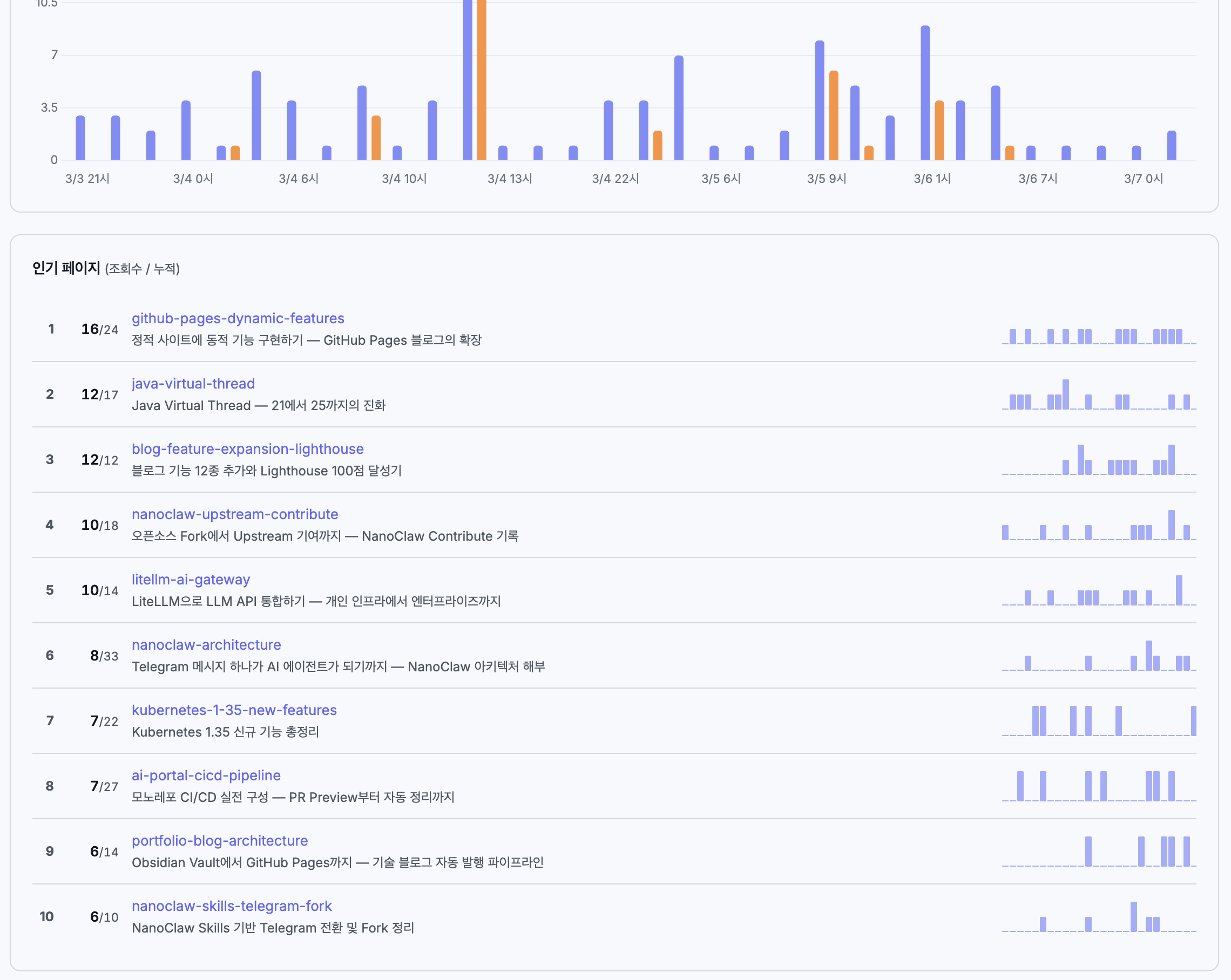
- 인기 페이지: GoatCounter 스타일(순위 + 조회수 + 경로 + 시계열 인라인 바)
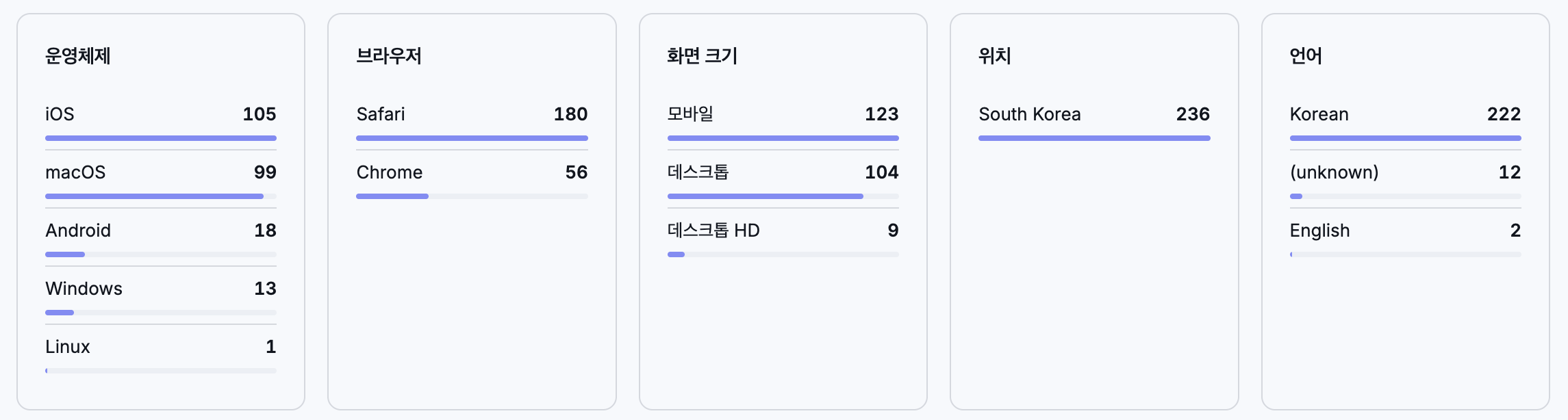
- 하단 5열: 운영체제, 브라우저, 화면크기, 위치, 언어
- 유입 경로 섹션은 삭제, 파스텔톤 색상으로 통일
vibe coding이라고 해서 AI에게 전부 맡기는 것이 아니다. 원하는 결과물의 청사진을 사람이 설계하고, 구현을 AI에 위임하는 구조다. 이 청사진의 구체성이 결과물 품질을 결정한다.
Claude Code plan mode
이 프롬프트를 Claude Code의 plan mode로 넘기면 AI가 구현 계획을 수립한다. 사용자의 구체적인 청사진이 있었기 때문에 plan도 구체적으로 나왔다.
- 사전 작업: CWV rating dimension 존재 여부를 GraphQL introspection으로 확인하고, 없으면 클라이언트 측 threshold 추정으로 fallback
- Workers API 변경(6개 항목): 기간별 동적 interval(5분/시간/일 분기), Web Analytics 시계열 + CWV 비율 데이터, 인기 페이지 2단계 순차 쿼리(top 10 집계 후 해당 slug 시계열 조회), GoatCounter locations/languages 추가, 응답 구조 재설계
- Dashboard UI 변경(3개 항목): HTML 구조 재설계(7개 섹션 순서 지정), JS 렌더링(Chart.js 스파크라인, 게이지바, 시계열), CSS(그리드, 파스텔톤, 반응형)
- 변경 파일 2개:
workers/likes/src/index.ts(API)와src/pages/dashboard.astro(UI) - 8단계 구현 순서 + 7개 검증 항목
plan을 승인하고 일괄 실행했다.
일괄 구현, 그리고 디버깅의 시작
잘 정리된 plan이라 구현까지는 순조로웠다. 첫 일괄 구현에서 Workers API와 대시보드 UI를 한꺼번에 변경했다. 그런데 막상 브라우저에서 열어보니 하나씩 문제가 발견되기 시작했다. 최종적으로 9개 이슈를 14커밋에 걸쳐 수정했는데, 이 디버깅 과정이 전체 작업 시간의 70%를 차지했다.
이 중 깊이 있게 다룰 만한 세 가지를 골라 기록한다.
무지의 영역: Astro scoped CSS 함정
가장 시간을 많이 소비한 이슈였다. 대시보드의 모든 동적 요소(차트, 인기 페이지 목록, 통계 카드)에 CSS가 전혀 적용되지 않았다. 클래스명은 정확한데 스타일이 먹지 않는 상황이었다.
원인은 Astro의 스코핑 메커니즘에 있었다. Astro의 <style> 블록은 빌드 타임에 data-astro-cid-xxx 속성을 각 요소에 부여하고, CSS 셀렉터에도 이 속성을 추가한다. 그런데 JavaScript의 innerHTML로 동적 생성한 요소에는 이 속성이 없다. Playwright로 DOM을 디버깅해서 이 속성 누락을 확인한 뒤, 동적 콘텐츠에 적용되는 모든 CSS 클래스를 :global() 래퍼로 감싸서 해결했다.
/* Before: Astro가 빌드 타임에 data-astro-cid-xxx를 추가 → innerHTML 요소에 매칭 안 됨 */
.chart-container { padding: 1rem; }
/* After: :global()로 스코핑 우회 */
:global(.chart-container) { padding: 1rem; }:global()은 Astro의 CSS 캡슐화를 무력화하므로 클래스명 충돌 리스크가 생긴다. 네이밍 컨벤션(예: dash- 접두어)으로 방어하거나, 동적 영역만 별도 <style is:global> 블록으로 분리하는 게 실무적인 타협이다. Astro에서 동적 콘텐츠가 많은 페이지를 만든다면 이 전략을 처음부터 세워야 한다.
경험, 짬밥 vs AI: GoatCounter API, 문서에 없는 파라미터 찾기
하단 5열(OS, 브라우저, 화면크기, 위치, 언어)의 데이터는 GoatCounter에서 가져오는데, 기간 필터가 동작하지 않았다. 공식 문서에는 /api/v0/stats/{page}의 기간 필터 파라미터가 기재되어 있지 않았다.
이 이슈에서 vibe coding 특유의 줄다리기가 발생했다.
AI: GoatCounter API 공식 문서에 기간 필터 파라미터가 없습니다. API에서는 지원하지 않는 것으로 판단됩니다. 기존 코드를 원복하겠습니다.
하지만 나는 GoatCounter 웹 UI에서 ?period-start=&period-end= 형식으로 날짜 범위 조회가 되는 걸 직접 확인한 상태였다. URL에 날짜를 넣으면 웹에서는 되는데 API에서 안 된다? 파라미터명이 다른 것일 뿐이라는 직감이 있었다.
나: 아냐.. GoatCounter 가서 조회해보니까
?period-start=2026-03-05&period-end=2026-03-06조회가 되는데..
AI: 웹 UI 전용 파라미터일 수 있습니다. API에서는 지원하지 않을 가능성이 높습니다.
나: 적극적으로 해줘… 안할려고 하지 말고
이 한마디 이후에야 상황이 바뀌었다. Workers에 디버그 엔드포인트를 만들어 start/end, from/to, rng, date-range 등 가능한 파라미터명을 순차적으로 테스트하기 시작했고, 결과적으로 start/end가 정답이었다.
# GoatCounter 미문서화 기간 필터 — 공식 문서에 없지만 동작하는 파라미터
curl "https://your-site.goatcounter.com/api/v0/stats/browsers?start=2026-03-01&end=2026-03-07" \
-H "Authorization: Bearer $GOATCOUNTER_TOKEN"공식 문서에는 없지만 API가 정상 응답하는 미문서화 파라미터였다. 다만 미문서 API에 의존하는 리스크가 있다. GoatCounter가 업데이트하면 예고 없이 깨질 수 있다. fallback으로 전체 기간 데이터를 가져와 클라이언트에서 필터링하는 로직을 준비해 두었다.
AI가 “안 된다”고 결론 내린 지점에서 사람이 “될 것 같으니 더 파봐라”고 방향을 잡아주는 것, 이것이 vibe coding에서 사람의 역할이다.
한 땀 한 땀 테스트: Zone Analytics GraphQL의 시간 범위 제한
Cloudflare Web Analytics 대시보드에는 HTTP 요청수, 4xx, 5xx 에러율이 깔끔하게 표시된다. 눈에 보이는 걸 그대로 옮기기만 하면 될 줄 알았다. 하지만 웹 대시보드에서 보이는 것과 API로 가져오는 것은 전혀 다른 문제였다.
30일치 HTTP 통계를 한 번에 가져오려 했더니 “시간 범위가 86400초를 초과할 수 없다”는 에러가 돌아왔다. Cloudflare Zone Analytics GraphQL에는 용도별로 여러 노드가 있는데, 각각 지원하는 시간 범위가 다르다. 문제는 Cloudflare 대시보드가 내부적으로 어떤 노드를 쓰는지 공개하지 않는다는 것이다. 결국 노드 3종을 기간별로 하나씩 바꿔가며 테스트했다. 24시간은 시간별 노드, 7일/30일은 일별 노드가 정답이었다.
그 외 자잘한 이슈들
하나하나는 단순하지만, 6개가 쌓이면 상당한 시간이 된다.
| 현상 | 원인 | 해결 |
|---|---|---|
| 차트가 렌더마다 무한 팽창 | Chart.js Canvas 크기 미제한 | responsive: true + 컨테이너 고정 |
| X축 168개 bar 오버플로 | 7일을 시간 단위로 표시 | 기간별 동적 버킷(5분/시간/일) |
평균 로드 235636ms 표시 | 마이크로초→밀리초 미변환 | /1000 추가 |
| CWV 좋음/나쁨 비율 없음 | GraphQL에 rating dimension 미존재 | 평균값 기반 클라이언트 추정 |
| 24시간 스파크라인 직선 | date dimension → 2포인트만 | datetimeHour로 변경 |
| 캐시 때문에 수정 미반영 | Workers caches.default 300초 | _nocache 파라미터 추가 |
솔직히 말하면, 나는 프론트엔드 지식이 약하다. 백엔드, 인프라, DevOps 쪽은 자신 있지만 CSS 그리드 비율이 깨지는 이유나 Chart.js Canvas가 무한 팽창하는 원인은 직감이 작동하지 않는 영역이다. 그래서 vibe coding이 더 의미가 있었다. AI가 코드를 짜고, 나는 브라우저에서 결과를 확인하고, 뭐가 이상한지만 짚어주면 된다. 프론트엔드 전문가가 아니어도 “이거 깨졌다”, “이 숫자가 이상하다”는 판단은 할 수 있다. 그 판단을 AI에게 전달하면 AI가 코드 레벨에서 원인을 찾고 수정한다. 모르는 영역에서의 끈기(한 땀 한 땀 테스트하고, 결과를 눈으로 확인하고, 다시 지시하는 반복)가 vibe coding의 실체다.
최종 결과
데이터소스 × 기간 필터 매트릭스
각 데이터소스가 기간(1d/7d/30d)에 따라 어떤 쿼리 방식을 사용하는지 정리하면 다음과 같다.
| 데이터 | 소스 | 1d | 7d | 30d |
|---|---|---|---|---|
| 추이, 인기 페이지 | Analytics Engine SQL | 5분 단위 | 시간 단위 | 일 단위 |
| 방문, PV, 로드, CWV | CF RUM GraphQL | datetimeHour | date | date |
| HTTP 요청, 4xx, 5xx | Zone Analytics GraphQL | httpRequests1hGroups | httpRequests1dGroups | httpRequests1dGroups |
| OS, 브라우저, 화면, 위치, 언어 | GoatCounter API | start/end | start/end | start/end |
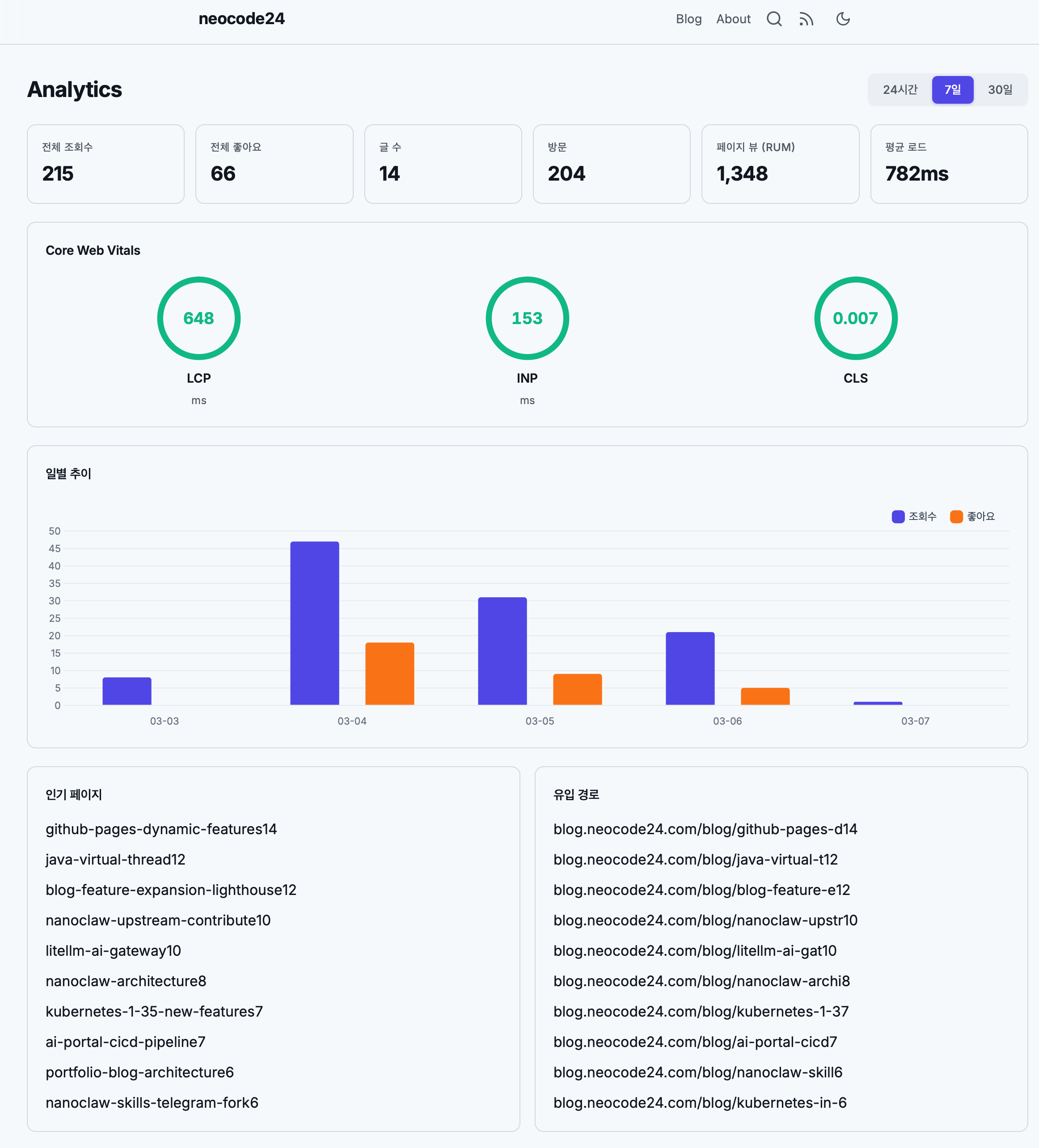
대시보드 레이아웃
[전체 조회수↑] [전체 좋아요] [글 수] [방문↑] [페이지 뷰↑] [평균 로드↓]
[Core Web Vitals ] [페이지 로드 ↓63%] [방문 ↑106%] [페이지 뷰 ↓2.7%]
[LCP 1.1s 게이지바 ] [요청 12,515 ↓26%] [4xx 3.44%] [5xx 1.85% ]
[INP 271ms 게이지바 ]
[CLS 0.004 게이지바 ]
[LCP 상세 99%/1%/0%] [INP 상세 88%/9%/3%] [CLS 상세 99%/1%/0%]
[추이 차트: 고정 x축, 30분/3시간/일 버킷]
[인기 페이지 (조회수/누적): 한글 제목 2행 + 시계열 인라인 바]
[운영체제] [브라우저] [화면크기] [위치] [언어]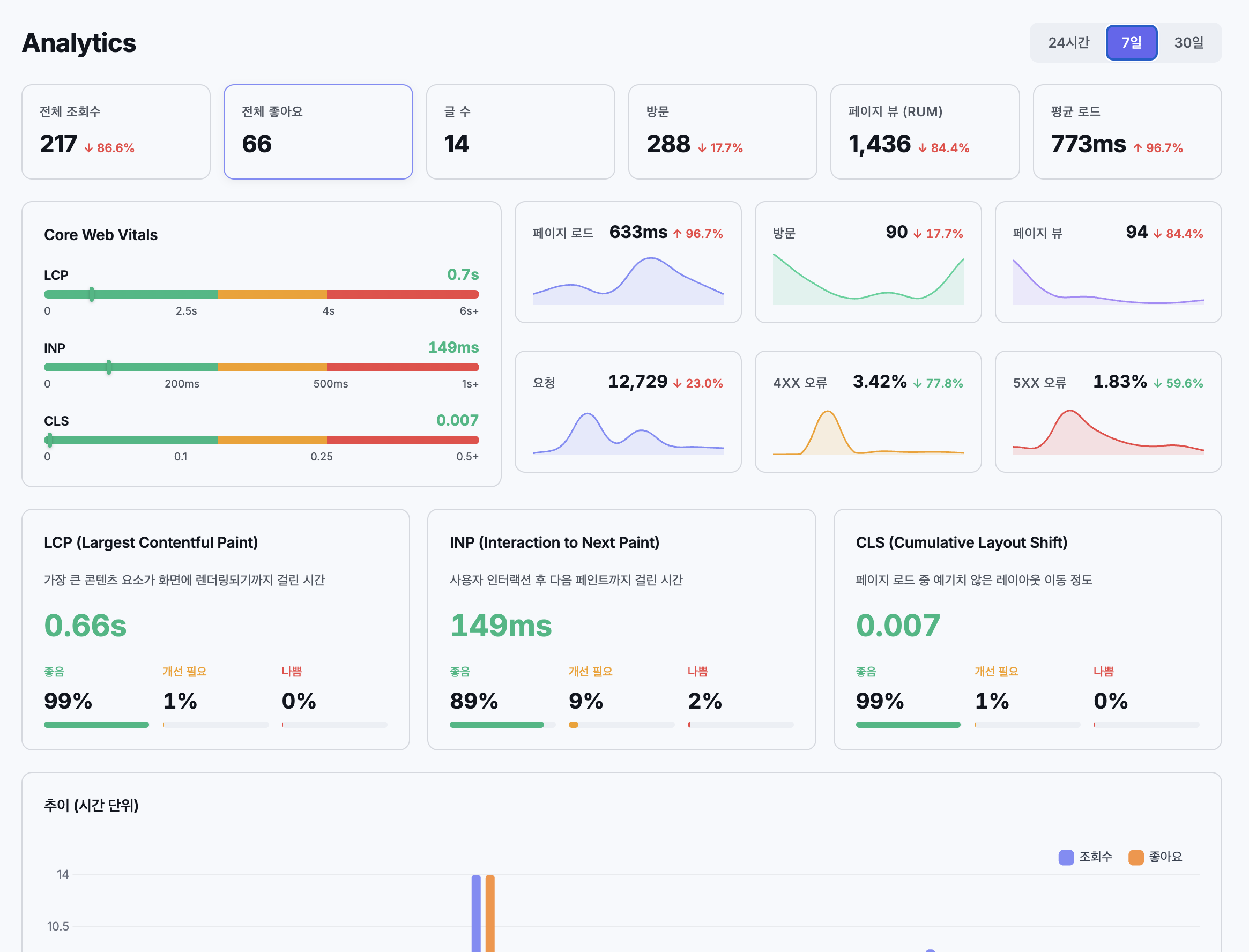
변경된 파일은 두 개뿐이다. Workers API(workers/likes/src/index.ts)에 약 200줄을 추가하여 4개 데이터소스를 집계하는 엔드포인트를 만들었고, 대시보드 UI(src/pages/dashboard.astro)에서 약 500줄을 변경하여 전체 레이아웃을 재설계했다.
수치로 보는 vibe coding
| 항목 | 값 |
|---|---|
| 작업 시간 | 약 6시간 (초도 3시간 + 후속 개선 3시간) |
| 총 커밋 | 35회+ |
| 첫 일괄 구현 후 fix/조정 커밋 | 29회+ |
| Claude Code 세션 | 4회 (context 소진으로 전환) |
| 토큰 소비 (추정) | Opus 4.6 기준 ~300K input + ~100K output (초도) |
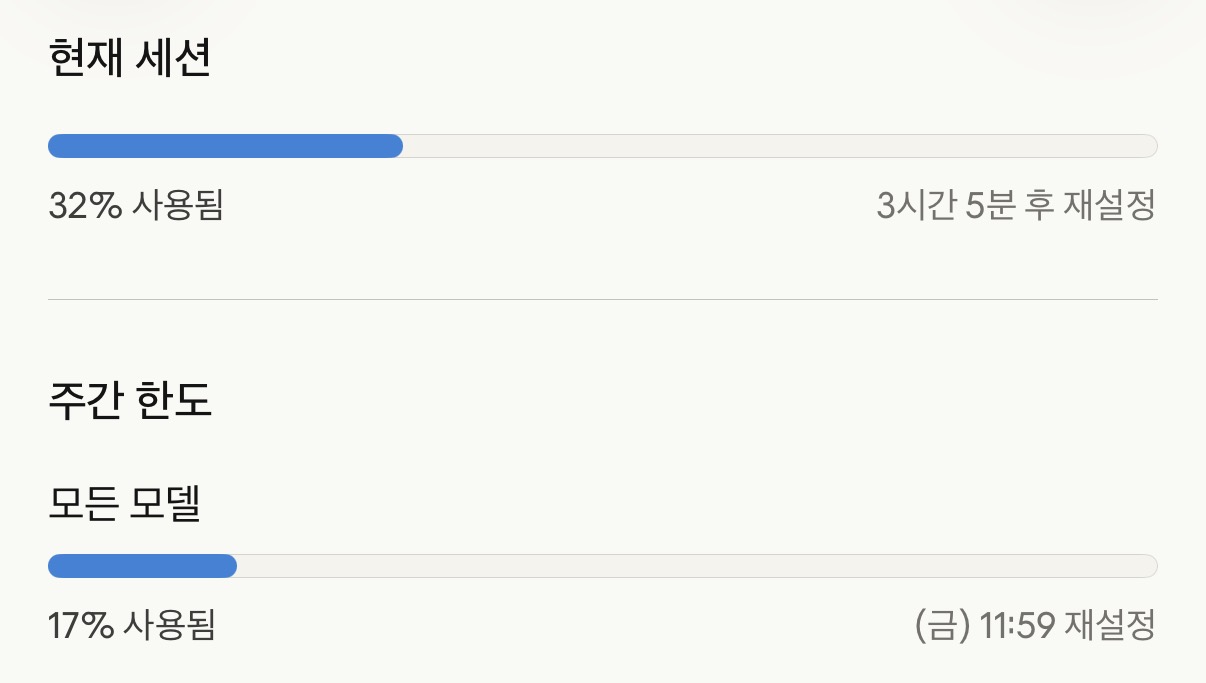
Claude MAX $100 Plan 기준, 이 작업 하나로 주간 한도가 0%에서 17%로 올라갔다.
정리
솔직하게 돌아보면, 디버깅에 시간이 많이 든 원인의 상당 부분은 AI의 한계가 아니라 사전 설계 부재였다. API 계약을 먼저 검증하지 않았고(GoatCounter 기간 필터, Zone Analytics 시간 범위 제한), Astro scoped CSS와 동적 DOM의 충돌을 사전에 고려하지 않았다. 작은 PoC로 각 API의 동작을 먼저 확인했다면 디버깅 커밋 29회 중 상당수를 줄일 수 있었다. “AI가 못해서”가 아니라 “사람이 사전 작업을 안 해서” 디버깅 지옥에 빠진 것이다.
vibe coding이 유효한 조건. 이 사례는 개인 블로그 대시보드라는 낮은 리스크 환경에서, Cloudflare+GoatCounter+Astro+Workers라는 특수한 조합으로 진행된 것이다. 프로덕션 환경, 팀 프로젝트, 또는 익숙한 스택이라면 vibe coding보다 사전 설계+테스트 전략이 더 효율적이다. vibe coding이 빛나는 건 도메인을 잘 모르는 영역에서 빠르게 프로토타이핑할 때다. 나에게는 프론트엔드가 그런 영역이었다.
6시간 35커밋은 빠른 건가? 솔직히 모르겠다. 같은 대시보드를 프론트엔드 경험자가 직접 만들면 디버깅이 줄어 4~5시간일 수 있고, 나 혼자 AI 없이 했으면 CSS와 Chart.js에서 훨씬 더 걸렸을 것이다. vibe coding의 가치는 “빠르다”가 아니라 “모르는 영역에서도 결과를 낼 수 있다”에 있었다.
context window가 한계에 도달하면서 Claude가 갑자기 일본어로 응답하기 시작한 에피소드도 있었다. 긴 vibe coding 세션에서는 context 소진에 의한 예상치 못한 부작용이 생길 수 있다.