주간 기술 뉴스 2026. 05. 23
목차
Kubernetes 1.36 후속 해설: Workload-Aware Scheduling과 Sharded Watch | Claude Code
/goal장기 실행 루프 | AAIF와 kagent의 에이전트 거버넌스 | LiteLLM Agent Platform과 Cloudflare LLM 추론 최적화
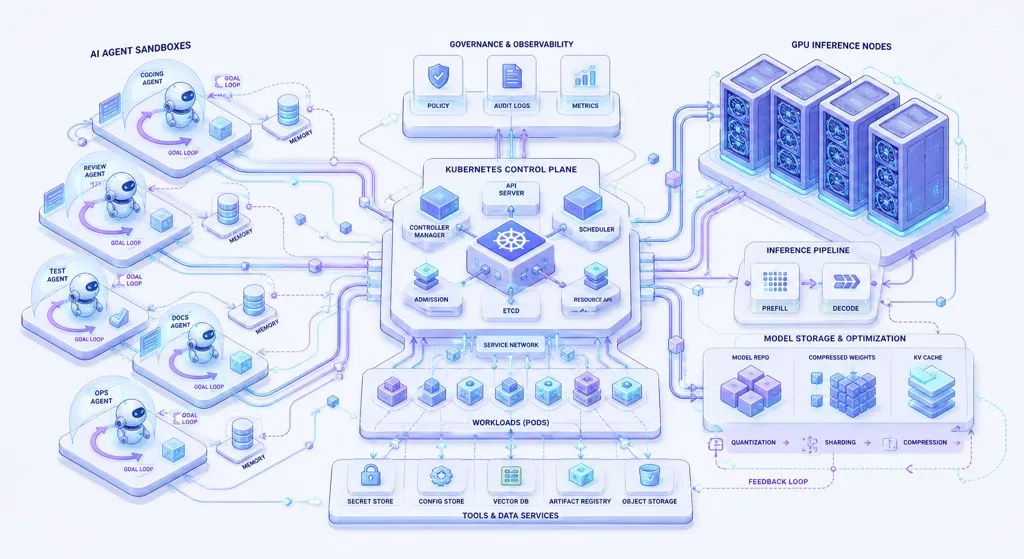
지난 주는 Kubernetes가 AI 에이전트 실행 환경을 인프라 레이어로 받아들이는 흐름을 다뤘다. 이번 주는 그 흐름이 두 갈래로 더 분명해졌다. 하나는 Kubernetes 자체가 대규모 AI/HPC 워크로드를 더 잘 다루기 위해 스케줄링과 API 서버 확장성을 정리하는 흐름이고, 다른 하나는 Claude Code와 Managed Agents처럼 개발 에이전트가 단발성 도구에서 장기 실행 루프로 이동하는 흐름이다.
원문 노트에는 Kubernetes 1.36 릴리스가 5월 21일 항목으로 적혀 있었지만, 공식 릴리스 글 기준 v1.36 “Haru”는 2026년 4월 22일에 공개됐다. 다만 5월에는 v1.36의 핵심 기능을 설명하는 후속 글이 이어졌고, 이번 글에서는 그 후속 흐름을 중심으로 정리한다.
Kubernetes & Cloud Native — 대규모 워크로드를 위한 두 가지 병목 정리
Kubernetes v1.36 공식 릴리스는 70개 enhancement를 포함했다. 그중 Stable 18개, Beta 25개, Alpha 25개라는 구성이며, 이번 릴리스에서 눈에 띄는 축은 보안 격리, 선언형 admission, DRA, 그리고 워크로드 단위 스케줄링이다.
User Namespaces Stable — 컨테이너 내부의 root를 호스트의 비권한 사용자로 매핑한다. 컨테이너 탈출 취약점이 발생해도 호스트 노드의 root 권한으로 바로 이어지지 않도록 하는 방어층이다. 이 기능 하나로 컨테이너 보안이 완성되는 것은 아니지만, 멀티테넌트 클러스터에서 root-in-container 문제의 기본 위험을 낮추는 표준 프리미티브가 됐다.
MutatingAdmissionPolicy Stable — 리소스 mutation을 외부 웹훅 대신 API 서버 안의 CEL 정책으로 처리할 수 있다. 운영 관점에서는 웹훅 서버의 가용성, 네트워크 호출, 버전 관리 복잡도를 줄일 수 있다. 모든 웹훅을 대체한다기보다, 공통 mutation 로직을 네이티브 정책으로 흡수하는 경계가 생겼다고 보는 편이 정확하다.
DRA 기능 성숙 — Dynamic Resource Allocation은 v1.34에서 GA가 된 뒤 GPU, TPU, NIC 같은 장치 자원을 선언적으로 다루는 기반이 됐다. v1.36에서는 DRA admin access와 prioritized list 같은 기능이 Stable로 이동했고, 워크로드와 ResourceClaim을 연결하는 기능이 Alpha로 확장됐다. 지난 주에 다룬 Hypercluster나 GKE Agent Sandbox와 연결해 보면, Kubernetes가 일반 컨테이너뿐 아니라 고가의 이종 자원 워크로드를 다루는 제어 평면으로 확장되는 흐름이다.
이번 주에 특히 볼 만한 후속 글은 두 개다.
첫 번째는 Server-Side Sharded List and Watch다. 기존에는 컨트롤러를 수평 확장해도 각 replica가 API 서버에서 전체 이벤트 스트림을 받아온 뒤 자기 shard가 아닌 객체를 버리는 구조였다. replica 수를 늘릴수록 처리량은 나뉘지만, API 서버와 네트워크가 보내는 총 이벤트 양은 줄지 않는다. v1.36의 Alpha 기능은 ListOptions에 shardSelector를 추가해 API 서버가 처음부터 shard 범위에 맞는 객체와 watch 이벤트만 보내도록 한다.
두 번째는 Workload-Aware Scheduling이다. 핵심은 Pod 하나씩 스케줄링하는 모델에서, 여러 Pod가 함께 의미를 갖는 Job이나 분산 학습 워크로드를 PodGroup 단위로 다루는 것이다. 특히 workload-aware preemption은 PodGroup 전체를 하나의 선점 단위로 본다. 분산 학습 Job 일부만 선점되어 전체 Job이 깨지는 실패 모드를 줄이기 위한 방향이다.
여기까지는 Kubernetes 내부의 변화다. 다음 흐름은 AI 에이전트가 Kubernetes 위에서 어떤 identity와 권한 모델을 가져야 하는지로 이어진다.
kagent는 이 흐름의 응용 레이어에 있다. Solo.io의 kagent는 Kubernetes 위에서 에이전트에 identity, orchestration, governance 계층을 붙이려는 런타임이다. 공식 설명은 “agent-on-behalf-of” 의미론, 검증 가능한 에이전트 identity, 정책 기반 action governance를 강조한다. 이는 단순히 에이전트를 Pod로 띄우는 문제가 아니라, 에이전트가 누구를 대신해 어떤 권한으로 무엇을 했는지 남기는 문제다.
AI Agent & LLM — 단발 실행에서 목표 기반 루프로 이동
이번 주 AI 에이전트 쪽에서 가장 직접적인 변화는 Claude Code의 /goal이다. /goal은 완료 조건을 세션에 설정하고, Claude가 각 turn 이후 그 조건이 충족됐는지 평가하면서 계속 작업하도록 만든다. 공식 문서 기준으로는 Claude Code v2.1.139 이상이 필요하며, 평가에는 작은 빠른 모델이 사용된다. 조건이 충족되지 않으면 그 이유가 다음 turn의 개선 지시로 들어간다.
이 변화는 단순 편의 기능보다 크다. 지금까지 CLI 코딩 에이전트의 기본 단위가 “프롬프트 하나 → 응답 하나”였다면, /goal은 “완료 조건 → 반복 실행 → 평가 → 재시도”를 제품 기능으로 노출한다. 사용자가 루프를 수동으로 돌리는 대신, 루프 자체가 인터페이스가 된다.
Anthropic의 Managed Agents도 같은 방향이다. Managed Agents 업데이트는 dreaming, outcomes, multiagent orchestration, webhooks를 공개했다. Dreaming은 지난 세션과 memory store를 주기적으로 검토해 반복 실수, 수렴한 workflow, 팀 선호를 memory로 정리한다. 장기 실행 에이전트에서 중요한 것은 한 번의 추론 품질만이 아니라, 여러 세션에 걸쳐 무엇을 보존하고 무엇을 버릴지다.
Multiagent sessions 문서는 이 구조를 더 구체적으로 보여준다. 여러 에이전트가 같은 container, filesystem, vault credentials를 공유하지만, 각 에이전트는 별도 session thread와 독립 context를 가진다. 도구, MCP 서버, context도 에이전트별 설정으로 분리된다. Code w/ Claude SF 2026 발표에서도 lead agent가 specialist subagent에 병렬 위임하고, 전체 흐름을 Claude Console에서 추적하는 모델이 언급됐다.
이 흐름은 멀티 AI 합의 기반 블로그 발행 파이프라인에서 다뤘던 “역할 분리”와도 맞닿아 있다. 과거에는 사람이 planner, executor, reviewer 역할을 도구 밖에서 조합했다면, 이제 제품 레벨에서 coordinator와 subagent, memory curator가 분리되고 있다.
Agent Standards — AAIF는 이번 주 뉴스라기보다 표준화의 배경이다
원문 노트에는 Agentic AI Foundation(AAIF) 출범이 이번 주 항목처럼 정리돼 있었지만, Linux Foundation의 공식 발표는 2025년 12월 9일이다. 따라서 이번 글에서는 “신규 출범”이 아니라, 2026년 에이전트 표준화 흐름을 해석하는 배경으로 다룬다.
AAIF의 핵심은 세 프로젝트가 같은 거버넌스 아래 들어갔다는 점이다.
- MCP — AI 모델과 도구, 데이터, 애플리케이션을 연결하는 프로토콜
- goose — Block의 local-first 오픈소스 에이전트 프레임워크
- AGENTS.md — repository 안에서 AI coding agent가 따라야 할 프로젝트별 지침을 담는 파일 포맷
Platinum members에는 AWS, Anthropic, Block, Bloomberg, Cloudflare, Google, Microsoft, OpenAI가 포함된다. 중요한 것은 이 조합이 “누가 모델을 갖고 있는가”보다 “에이전트가 도구와 프로젝트 컨텍스트를 어떤 방식으로 읽고 실행하는가”에 초점을 둔다는 점이다.
MCP가 tool/data 연결을 담당하고, AGENTS.md가 repository-local instruction을 담당하며, goose가 local agent runtime의 사례를 제공한다. 이 셋이 같은 재단 아래 묶이면 에이전트 생태계의 표준화 압력은 모델 API 바깥에서 만들어진다. 에이전트가 실제로 일하는 곳은 모델 호출 지점이 아니라 파일시스템, tool registry, 권한 경계, audit trail이 만나는 곳이기 때문이다.
Docker & Containers — 에이전트 샌드박스가 별도 플랫폼으로 분리된다
이번 주 원문 노트에서 가장 실용적인 항목은 LiteLLM Agent Platform이다. GitHub README 기준 이 프로젝트는 Claude Code, Codex, Hermes 같은 coding agent를 격리된 sandbox 안에서 실행하기 위한 self-hosted infrastructure다. 에이전트는 Kubernetes pod 안에서 뜨고, 실제 secret은 vault proxy가 outbound TLS 연결 시점에 교체한다. 에이전트 프로세스 안에는 stub credential만 보인다.
이 설계가 흥미로운 이유는 LiteLLM Gateway의 “모델 라우팅” 문제와 coding agent의 “실행 격리” 문제가 결합되기 때문이다. 모델 호출만 중앙화하는 것으로는 충분하지 않다. 에이전트가 shell, git, browser, API client를 들고 실행되면 필요한 것은 rate limit이나 cost tracking만이 아니라, filesystem 격리, credential mediation, session persistence, egress control이다.
Self-hosting 경로도 의도적으로 Kubernetes 중심이다. README는 sandbox가 kubernetes-sigs/agent-sandbox CRD를 통해 Kubernetes에서 실행되고, local dev는 kind를 사용한다고 설명한다. 빠른 시작도 bin/kind-up.sh와 docker compose up 조합이다. 이는 지난 주에 다룬 GKE Agent Sandbox와 같은 문제를 더 작은 self-hosted 플랫폼 형태로 푸는 접근이다.
구분하면 이렇다.
- GKE Agent Sandbox — 클러스터 운영자가 관리하는 managed Kubernetes 레이어의 에이전트 격리
- LiteLLM Agent Platform — coding agent harness를 격리 실행하기 위한 self-hosted control plane
- kagent — Kubernetes-native agent identity, orchestration, governance 런타임
셋은 경쟁 제품이라기보다 다른 레이어를 본다. 공통점은 에이전트를 “프로세스 하나”가 아니라 “권한과 수명주기를 가진 workload”로 취급한다는 점이다.
LLM Inference — Cloudflare는 메모리 병목과 단계 분리를 동시에 다룬다
Cloudflare의 이번 흐름은 에이전트 플랫폼과 직접 이어진다. 에이전트가 많아질수록 LLM 호출은 더 길고, 더 빈번하고, 더 구조화된다. 비용과 레이턴시를 모델 API 가격표만으로 해결하기 어렵다.
Cloudflare의 extra-large language model 인프라 글은 Workers AI에서 Kimi K2.5 같은 대형 모델을 다루기 위한 기반을 설명한다. 핵심은 prefill/decode disaggregation이다. LLM 요청은 입력 토큰을 처리하고 KV cache를 채우는 prefill 단계와, 출력 토큰을 생성하는 decode 단계로 나뉜다. prefill은 compute-bound, decode는 memory-bound에 가깝기 때문에 같은 머신에서 같이 처리하면 GPU 자원을 효율적으로 쓰기 어렵다. Cloudflare는 각 단계를 별도 inference server로 분리해 단계별로 조정하고 확장하는 접근을 택했다.
같은 글에서 Infire도 다시 등장한다. Infire는 Cloudflare의 Rust 기반 inference engine이며, multi-GPU 지원을 pipeline parallelism과 tensor parallelism으로 확장했다. Cloudflare 설명에 따르면 Kimi K2.5는 약 560GB의 model weight를 가지며, H100 8개로 실행할 수 있도록 Infire를 확장했다.
Unweight는 다른 병목을 겨냥한다. 단일 token 생성 시 모든 model weight를 GPU 메모리에서 읽어야 하므로, 병목은 compute가 아니라 memory bandwidth가 된다. Cloudflare는 lossless compression으로 model weight를 15-22% 줄이면서 bit-exact output을 유지하는 방식을 공개했다. 압축된 weight를 on-chip memory에서 풀어 tensor core로 바로 공급해 main memory 왕복을 줄이는 구조다.
이 두 글을 함께 보면 방향이 명확하다. 모델 추론 최적화는 단순히 더 빠른 GPU를 쓰는 문제가 아니다. prefill과 decode를 나누고, weight 이동량을 줄이고, cold start와 multi-GPU communication을 줄이는 식으로 시스템 전체를 다시 배치하는 문제다.
금주 하이라이트
Kubernetes v1.36 후속 해설 — 릴리스 자체는 4월 22일이지만, 5월에는 Sharded List/Watch와 Workload-Aware Scheduling 해설이 이어졌다. 대규모 클러스터에서는 API 서버 watch 비용이, AI/HPC 워크로드에서는 Pod 단위 스케줄링이 병목으로 드러난다.
Claude Code /goal — 완료 조건을 평가하는 작은 모델을 루프 안에 넣어, 사용자가 반복 지시를 하지 않아도 목표 달성까지 계속 실행한다. 코딩 에이전트 UX가 “명령”에서 “종료 조건” 중심으로 이동한다.
Managed Agents dreaming과 multiagent orchestration — memory 정리와 subagent 위임이 제품 기능으로 노출됐다. 장기 실행 에이전트에서 중요한 것은 단일 응답 품질보다 상태, 기억, 역할 분리다.
AAIF와 kagent — AAIF는 MCP, goose, AGENTS.md를 Linux Foundation 거버넌스 아래 묶었고, kagent는 Kubernetes 위에서 에이전트 identity와 policy를 다루려 한다. 표준화의 중심이 모델 API가 아니라 실행 컨텍스트와 권한 경계로 이동한다.
LiteLLM Agent Platform — coding agent를 Kubernetes pod sandbox 안에서 실행하고, vault proxy로 credential 노출을 줄인다. 에이전트 실행 인프라가 모델 gateway 바깥의 별도 계층으로 분리되고 있다.
Cloudflare Infire/Unweight — prefill/decode 분리와 weight compression은 에이전트 시대의 추론 비용을 줄이는 시스템 레벨 접근이다. 더 큰 모델을 더 자주 부르는 방향으로 워크로드가 이동할수록 이런 최적화가 플랫폼 경쟁력이 된다.